From Messy Files to Magic Answers: How RAG Makes AI Smarter (and Life Easier)
by Gabriel Vergara
Introduction
In the ever-expanding digital age, the sheer volume of information stored in documents can be overwhelming. For organizations, researchers, and developers, accessing relevant insights from extensive repositories of files can be a daunting task. This is where Retrieval-Augmented Generation (RAG) techniques shine, seamlessly blending the retrieval of contextual information with the power of generative AI to deliver precise and actionable answers.
At the heart of RAG lies the concept of vector stores—databases optimized for similarity search, enabling efficient retrieval of semantically relevant data. These vector stores serve as the backbone for extracting meaningful insights from unstructured data, making RAG a powerful tool for handling large volumes of textual information.
In this article, we’ll explore the theory behind RAG, its foundational components like vector stores, and its transformative potential across various domains. Whether you’re a developer, researcher, or AI enthusiast, you’ll leave with a deeper understanding of how RAG works and why it’s a game-changer for modern information processing.
Let’s dive into the fascinating world of RAG and unlock its potential together!
About RAG and vector stores
Retrieval-Augmented Generation (RAG) is an AI approach that combines the capabilities of language models with an external retrieval system to enhance the quality and accuracy of responses. In traditional language models, responses are generated based on pre-trained knowledge, which may lead to limitations in accuracy or relevancy, especially when handling domain-specific or up-to-date information. RAG solves this by augmenting the generation process with real-time data retrieval. Before generating a response, the model retrieves relevant documents or information from a structured dataset, such as a database or a vector store, and uses this external knowledge to craft more precise and relevant answers. This technique significantly improves performance in tasks like question answering, summarization, or any application where real-time and context-specific information is critical.
The steps of RAG
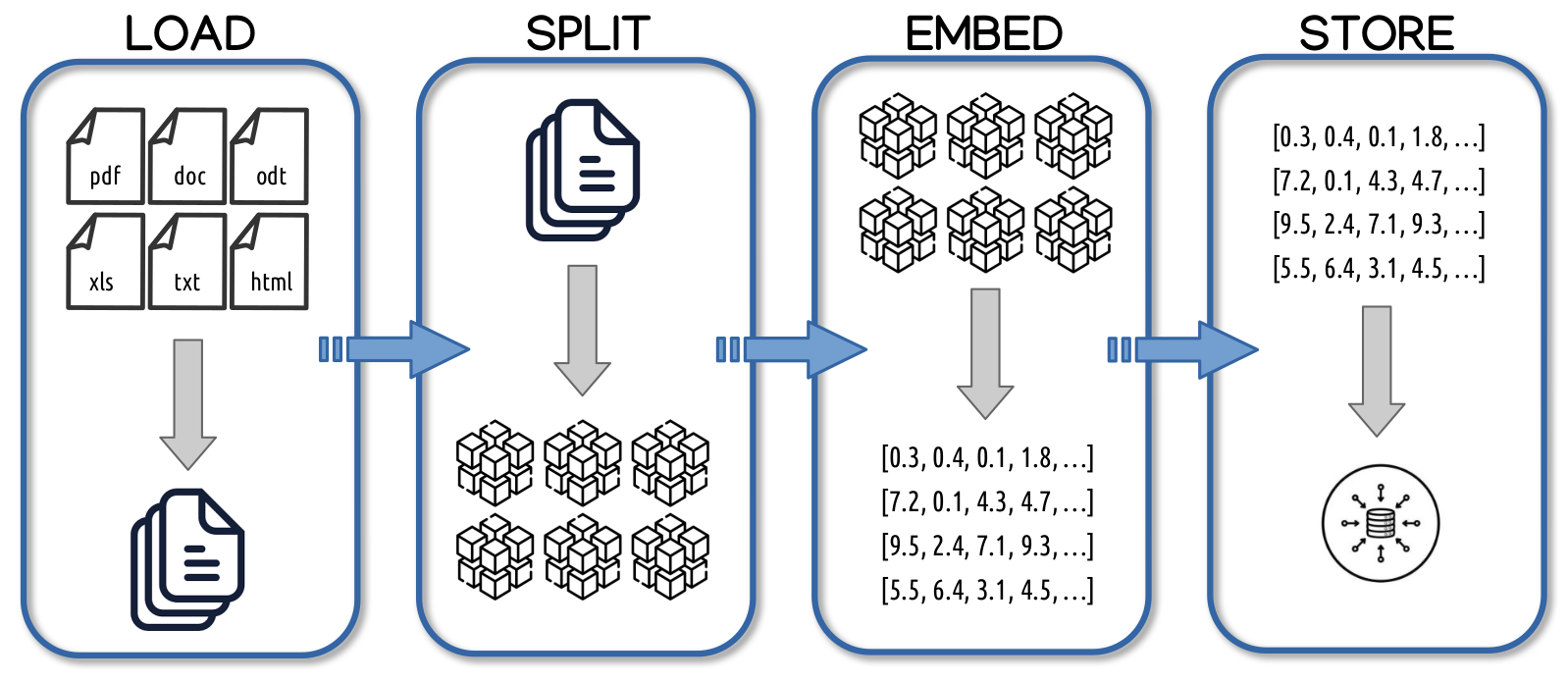
- Load Data: This is the first step where the relevant data is collected and brought into the system. The data could be in various formats, such as text documents, PDFs, or even structured databases. The goal of this step is to make the raw data accessible so that it can be processed in subsequent stages. In a RAG system, the quality and relevance of the data being loaded are crucial, as this is what the language model will eventually retrieve and use to augment its responses.
- Split Data: After loading the data, it often needs to be broken down into smaller, more manageable chunks. This is done because handling entire documents or large sections of text at once is inefficient and could reduce retrieval accuracy. Splitting the data into sections, paragraphs, or even sentences allows for more granular control when searching for relevant information during the retrieval phase. It also enables better vector representation, which is key in embedding the data for efficient similarity searches.
- Embed Data: Once the data is split into smaller chunks, each chunk is transformed into a numerical format (vector) through embedding. Embedding involves passing the text data through a model that converts it into high-dimensional vectors, which capture the semantic meaning of the text. This step is essential for enabling the RAG system to perform similarity searches. By embedding the data into vectors, the system can efficiently find which pieces of information are most relevant to a query by comparing vector similarities.
- Store Data: The final step involves storing the embedded data in a database or vector store (such as FAISS or Pinecone) that supports efficient similarity searches. This vector store allows the system to quickly retrieve the most relevant data chunks based on a query or prompt. When a query is made, the RAG system searches through the stored embeddings, retrieves the most semantically similar pieces of information, and uses this retrieved data to augment the generation from the language model.
Together, these steps ensure that a RAG system can retrieve relevant information in real-time, significantly improving the quality and relevance of the responses generated by a language model.
Fattening the Prompt with RAG
One of the core strengths of RAG lies in its ability to enhance LLM outputs by injecting external context retrieved from a vector store. This process, that I often refer to as fattening the prompt, ensures that the LLM has access to the most relevant, domain-specific information when responding to a query. By coupling retrieval with generation, RAG overcomes the limitations of traditional LLMs, which rely solely on pre-trained knowledge.
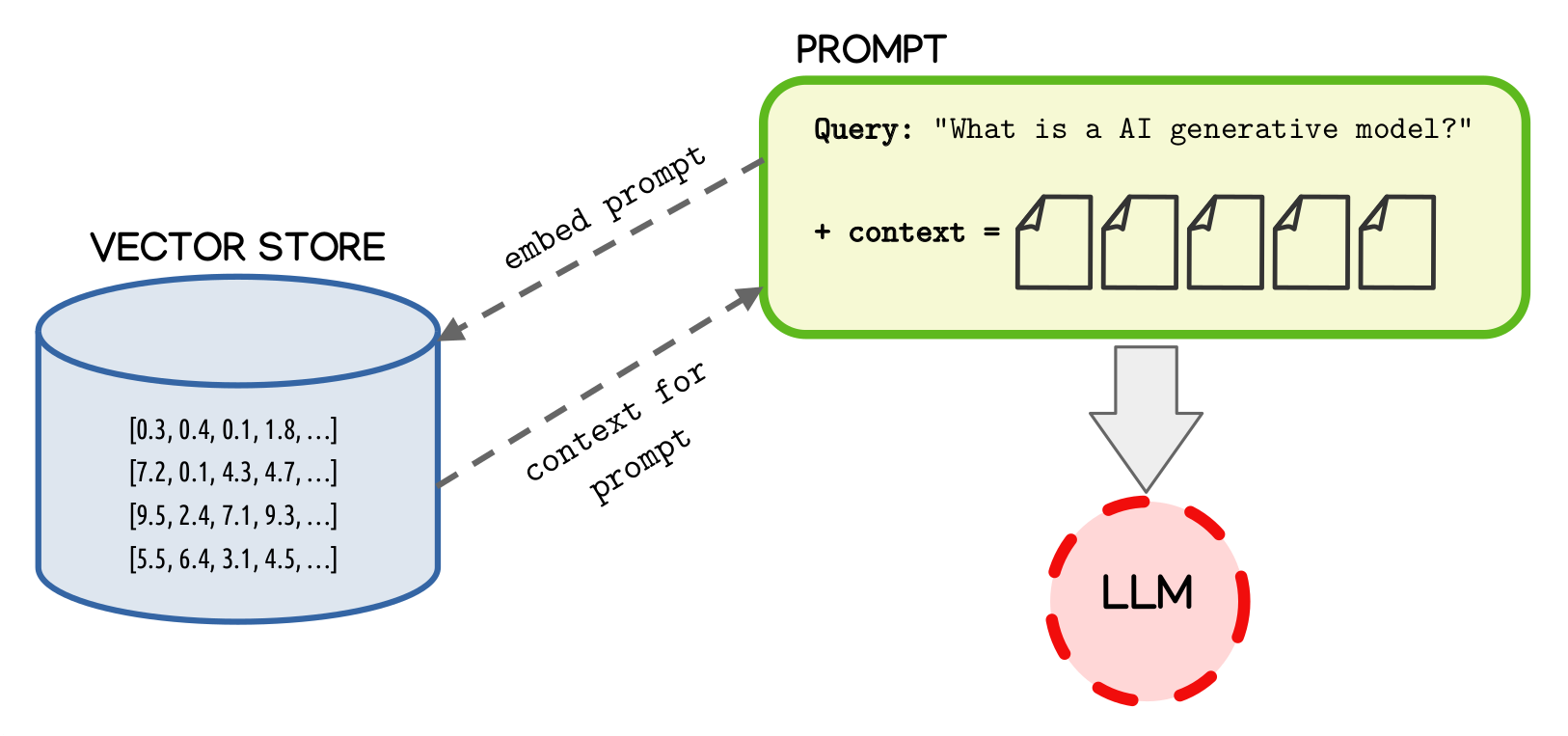
When a user poses a question, the RAG pipeline performs the following key operations:
- Querying the Vector Store: The user’s question is transformed into an embedding—a high-dimensional vector representation of the query’s semantic meaning. This embedding is then compared against the stored vectors in the vector database to identify the most semantically similar chunks of information. These chunks represent the context most relevant to the user’s question.
- Retrieving Context: Once the relevant chunks are identified, they are retrieved from the vector store and added as supplementary context to the original user prompt. This enriched prompt provides the LLM with the specific knowledge it needs to generate an accurate and context-aware response.
- Generating the Response: The LLM processes the fattened prompt, which now includes both the user’s question and the retrieved context. By leveraging this additional information, the model can produce a response that is not only more accurate but also grounded in the retrieved data, ensuring relevance and precision.
For example, imagine querying a documentation assistant about a specific technical detail in a large corpus of manuals. Without RAG, the LLM might generate a generic or even incorrect response. With RAG, the assistant retrieves the exact sections of the manual containing the relevant details, feeding them into the prompt and allowing the model to produce a precise answer.
This combination of retrieval and generation transforms the LLM into a robust, context-aware assistant capable of handling domain-specific inquiries with ease. The power of fattening the prompt lies in its ability to provide the LLM with the exact knowledge it needs, precisely when it needs it, elevating the quality of interaction and utility of the system.
Conclusion
Retrieval-Augmented Generation (RAG) represents a transformative approach to managing and extracting insights from vast collections of unstructured data. By combining the precision of information retrieval with the generative capabilities of modern AI, RAG enables seamless access to relevant, contextualized answers across various domains.
A core strength of RAG lies in its adaptability. Its modular nature allows it to be applied to diverse use cases, whether in corporate environments, academic research, or personal knowledge management. Beyond its immediate benefits, RAG opens doors to a future where the barriers to accessing knowledge are significantly reduced, enabling greater efficiency and innovation.
As you’ve seen, understanding the foundational principles of RAG, including the importance of embedding spaces, vector-based retrieval, and generative AI, is key to unlocking its full potential. This theory serves as a starting point for exploring how these concepts can be tailored to specific challenges or domains.
The potential is immense—so keep learning, exploring, and imagining what you can achieve with RAG. The journey has just begun!
About Me
I’m Gabriel, and I like computers. A lot.
For nearly 30 years, I’ve explored the many facets of technology—as a developer, researcher, sysadmin, security advisor, and now an AI enthusiast. Along the way, I’ve tackled challenges, broken a few things (and fixed them!), and discovered the joy of turning ideas into solutions. My journey has always been guided by curiosity, a love of learning, and a passion for solving problems in creative ways.
See ya around!